- Here is the link to the sharable GitHub repo with codes: [Link].
- Here is the link to the full project report: [Link].
- How can we extract significant attributes from textual descriptions of each product?
- Once these attributes are identified, how can they be leveraged to refine product search capabilities, and what is the extent of improvement in search results by incorporating these attributes?
- Additionally, how can we devise an effective method to visualize the relationships between product attributes and the relatedness of different products?
- Feature Selection: In the future, Cymax could expand their data inputs beyond what was provided, potentially incorporating image data into the pipeline.
- Model and Metric: Various similarity models and metrics exist, and more may emerge. While we opted for cosine similarity, this component of the pipeline can be adapted to suit different requirements.
- Validation and Testing: This stage should include a mix of similar and non-similar products. As Cymax's product range grows, the testing and validation process can evolve to incorporate a broader and more diverse range of products, including new and niche items.
- Aumüller, M., Bernhardsson, E. ve Faithfull, A. (2018). ANN-Benchmarks: A Benchmarking Tool for Approximate Nearest Neighbor Algorithms. https://arxiv.org/abs/1807.05614 adresinden erişildi.
- Bernhardsson, E. (2017). ANNOY Spotify Repository. GitHub repository. https://github.com/spotify/annoy adresinden erişildi.
- DeBlois-Beaucage, J. (2021). Building a Recommender System Using Graph Neural Networks. Medium. https://medium.com/decathlondigital/building-a-recommender-system-using-graph-neural-networks-2ee5fc4e706d adresinden erişildi.
- Deivasigamani, K. (2020). Retail Graph — Walmart’s Product Knowledge Graph. Medium. https://medium.com/walmartglobaltech/retail-graph-walmarts-product-knowledge-graph-6ef7357963bc adresinden erişildi.
- Nickel, M. ve Kiela, D. (2017). Poincaré Embeddings for Learning Hierarchical Representations. I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan ve R. Garnett (Ed.), Advances in Neural Information Processing Systems içinde (C. 30). Curran Associates, Inc. https://proceedings.neurips.cc/paper_files/paper/2017/file/59dfa2df42d9e3d41f5b02bfc32229dd-Paper.pdf adresinden erişildi.
- Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., … Duchesnay, E. (2011). Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12, 2825-2830.
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … Liu, P. J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. https://arxiv.org/abs/1910.10683 adresinden erişildi.
Abstract
In this UBC Capstone research project, we endeavored to assist Cymax in constructing a knowledge graph for identifying furniture items with shared or complementary features through an analysis of product titles and descriptions. Our approach centered on employing named-entity recognition (NER) within a comprehensive data science pipeline. This pipeline initiates by extracting named entities from product descriptions through a refined NER model. It then assesses the similarities between products based on these entities and other relevant features. A significant outcome of our project is the development of a dashboard and a Neo4j database for a product knowledge graph, enabling visual representation of product similarities. The NER model we developed demonstrated solid performance, validated both by the entity F1 metric and human assessment. The meaningful connections established through the identified entities contribute to a more nuanced understanding of product relationships. Integrating our project outcomes with Cymax's existing product analytics is anticipated to elevate customer experience and maximize the value derived from their textual data.
Note: The original data, deployed database (Neo4j and later AWS Neptune) and dashboard are privately owned by Cymax and unable to share publicly.
Introduction
Cymax Group Technologies, an eCommerce company, offers a sophisticated software-as-a-service platform to furniture vendors and retailers. Their extensive database comprises over 600,000 furniture items, each featuring unique attributes such as price, promotional status, dimensions, weight, and detailed textual descriptions, including product titles and descriptions. Here is one example of our texual data about product descriptions:
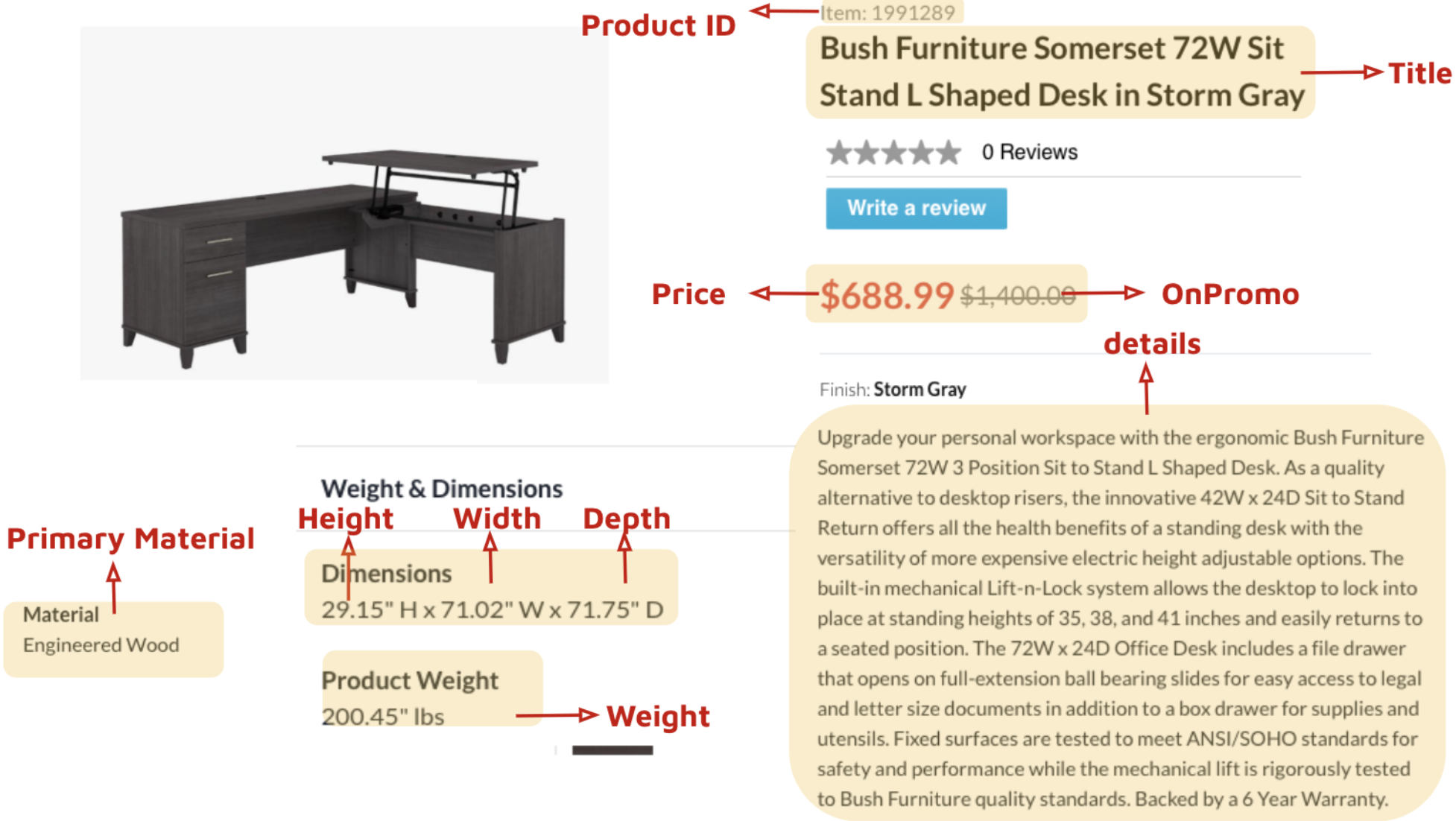
While their current platforms utilize the tabulated data of these furniture items, the rich information embedded in the textual descriptions remains largely unexplored. Tapping into this wealth of information can empower Cymax to unlock deeper insights into their product catalog, significantly enhancing the efficiency and accuracy of their search and recommendation systems.
Our project was methodically divided into three progressive milestones, cumulatively leading to the creation of a final data product tailored for Cymax. The key questions guiding our project were:
Milestone 1 - Named-entity Recognition (NER) for Product-Entity
Our project aimed to refine product discovery by extracting meaningful attributes from descriptions, filtering out non-informative marketing phrases while preserving the semantic significance of relevant features. Standard models like BERT SentenceTransformer, bag-of-words, or word2vec were inadequate for this task due to their limited ability to process entire text columns effectively. Inspired by Walmart’s methodology in their product knowledge graph article (Deivasigamani, 2020), we opted to apply a similar approach for attribute extraction and established a custom Named-entity Recognition (NER) system for this purpose.
The custom NER task involved fine-tuning a pre-trained BERT language model. In partnership with our collaborators, we identified seven key entities: ‘Color’, ‘Type’, ‘Additional Material’, ‘Appearance’, ‘Style’, ‘Feature’, and ‘Notice’. Given the dataset’s diversity, encompassing 258 unique product subcategories and 72 general types, we faced the challenge of achieving a representative sample size. To address this, we had two annotators manually label 200 randomly chosen product descriptions according to our NER guidelines.
To maintain consistency and accuracy in our annotators' work, we adapted the Inter-annotator Agreement (IAA) metric, modifying the cohen_kappa_score from scikit-learn (Pedregosa et al., 2011) for multiple tags and annotators. This resulted in a new IAA score metric. Our IAA score reached 85.5%, indicating a high level of annotator agreement.
For the modeling phase, considering the lack of pre-existing models for Cymax’s specific needs and resource constraints, we opted to fine-tune a large language model for our custom NER task. We tested four bidirectional models (bert-base-uncased, bert-large-uncased, dslim/bert-base-NER, Jean-Baptiste/roberta-large-ner-english) to analyze product descriptions contextually. The best-performing model was selected based on its performance on an unseen validation set of 50 additional tagged examples. We assessed model quality using the exact match F1 score, aligning with Cymax's requirements for both precision and recall. We evaluate our NER model performance using the metrics proposed in Message Understanding Conference 5 (MUC-5) (Chinchor ve Sundheim, 1993). Here an entity tagged is marked as correct when it is able to assign the right tag to an entity, and if it finds the correct starting and ending entity boundaries. Based on the F1 score with exact match, the results for our 4 large language models are as follows:

Our analysis revealed that while the BERT large and BERT base models had similar performance levels, the BERT large model required longer runtime. Consequently, we chose the BERT base model as our optimal choice, with a test F1 score of 76% and an unseen validation F1 score of 80%. Below is one labeling example of our best LLMs versus the original human labeling:

This model enables Cymax to efficiently extract key entities from new furniture products in their database. However, it's important to consider the model's potential limitations in generalizing to niche furniture products. For specialized or novel items, Cymax might need to retrain the model with different samples and entity tags to ensure optimal performance for their specific data requirements.
Milestone 2 - Product-Product Similarity
In this phase of our project, we developed an 'experimentation pipeline' for Cymax, designed to accommodate different models and transformation pipelines. This aims to future-proof their process, allowing for the integration of new data and models over time. We identified three key areas for built-in flexibility in this process:
To showcase the effectiveness of our experimentation pipeline, we used it to explore the impact of augmenting NER features with other features in identifying similar products. Our process began with converting text features into sentence embeddings. After extracting entities, we refined them by removing duplicates and special characters, applied lemmatization, and then converted them into sentences for embedding using BERT. For product similarity assessment, we employed Spotify’s Approximate Nearest Neighbor model, ANNOY (Bernhardsson, 2017), due to its straightforward implementation and open-source nature.
We developed three following pipelines: a control model and two experimental models.
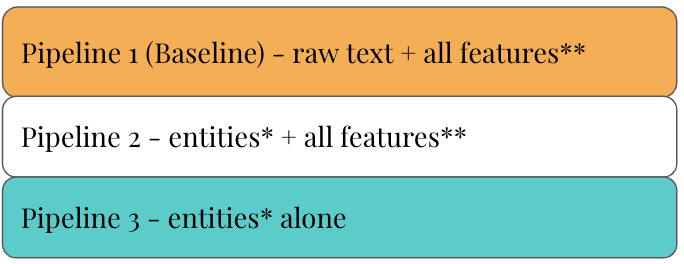
We developed three models: a control model and two experimental models. The control model used sentence embeddings from the raw text (product titles and descriptions). The first experimental model incorporated all features (processed tagged entities, numeric features, promotional status, and the 'PrimaryMaterial' category), while the second experimental model utilized only the seven processed entities. To validate these models, we created a list of similar products based on Cymax's product grouping data and analyzed the similarity scores. The results, including pairs of similar products with their similarity scores using different feature combinations, are illustrated below:
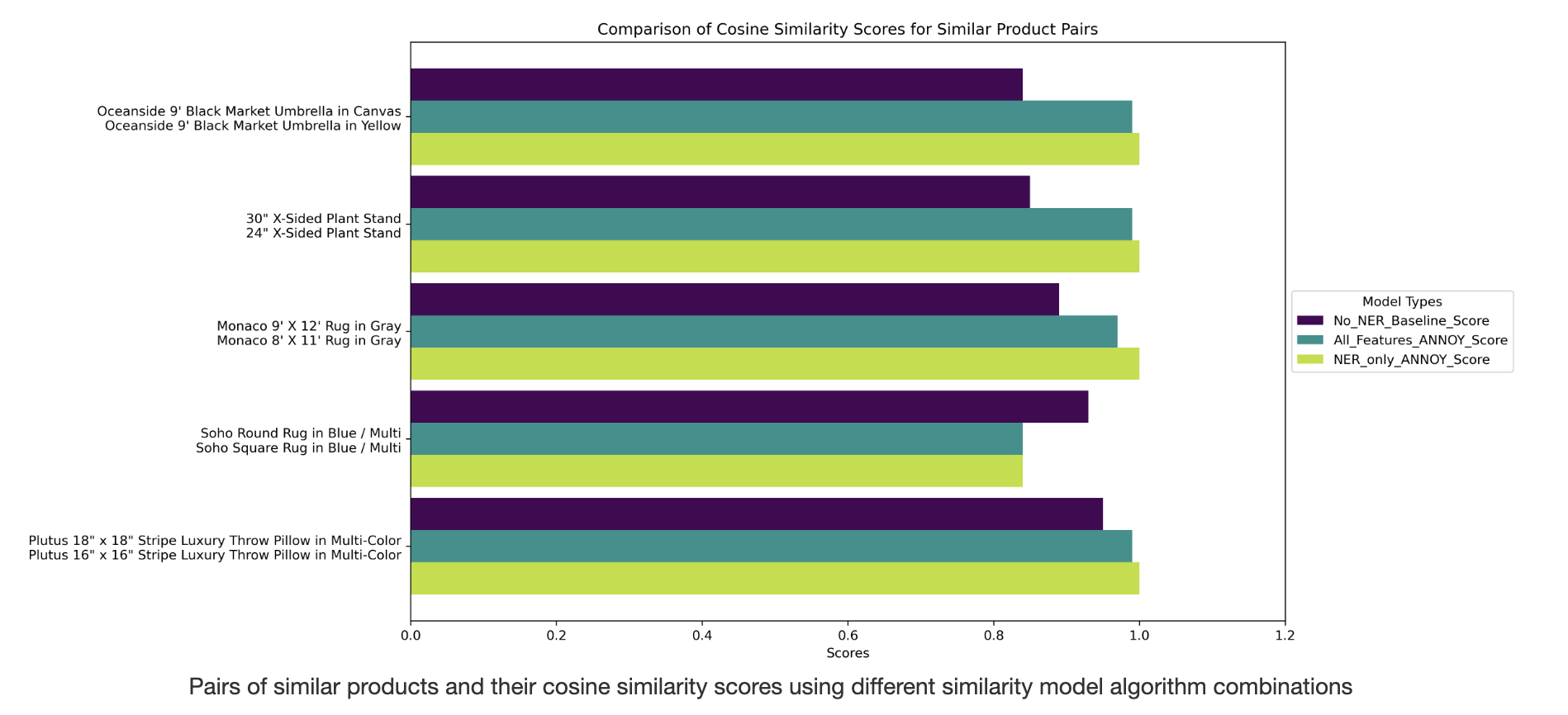
Analysis of the graph reveals that the model using only extracted entity features assigned a perfect similarity score (1.0) to the most similar products, even in cases of size differences or untagged attributes. This indicates that the model might be oversimplified, suggesting the need for additional entity tags in the future to capture more nuanced differences like size or dimensionality. Both experimental models outperformed the control model (which used raw text without NER), highlighting the importance of NER in improving similarity metrics. However, it's evident that combining NER with other features is crucial to prevent overestimation of product similarity. In summary, our findings confirm that NER enhances similarity assessments, and its integration with other features is necessary for more accurate estimations of product similarity.
Milestone 3 - Product Knowledge Graph (PKG)
Traditional recommendation systems often struggle with complex product relationships, handling intricate queries, and accurately reflecting real-world many-to-many relationships. To address these challenges, we opted for a graph-based database, renowned for its ability to manage complex product-product and product-entity relationships effectively. This approach also offers scalability, crucial for handling intricate real-world product connections. Employing a knowledge graph database, we aim to enhance the precision and stability of our recommendation system. This database forms the backbone for various downstream tasks, such as recommending complementary products.
A knowledge graph consists of vertices (nodes) and edges. For our purposes, we chose three types of nodes – product, category, and entity – and two types of relationships as edges: product-product and product-entity. The product-product edges are based on product similarities derived from the similarity scores in Milestone 2. Product-to-entity edges, on the other hand, stem from the relationships identified between products and entities through NER.
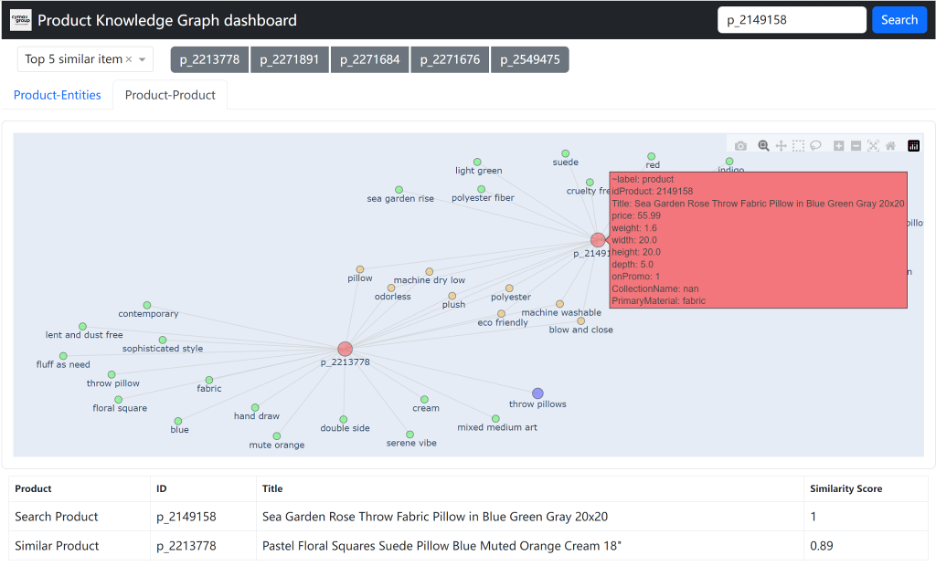
To enable Cymax to assess the entities extracted from NER and their significance in determining product-product similarity, we developed a product knowledge graph dashboard. This dashboard features a search bar in the upper right corner, allowing product searches by product ID. It also displays the entities related to a specific product, as illustrated in the Figure below:
Selecting the 'Product-Product' tab automatically generates tabs for the top five similar products. Clicking on a tab for a specific item displays a knowledge graph showing the connections between the searched product and the chosen similar product, with overlapping entities highlighted. An example of this visualization is shown in the Figure below:
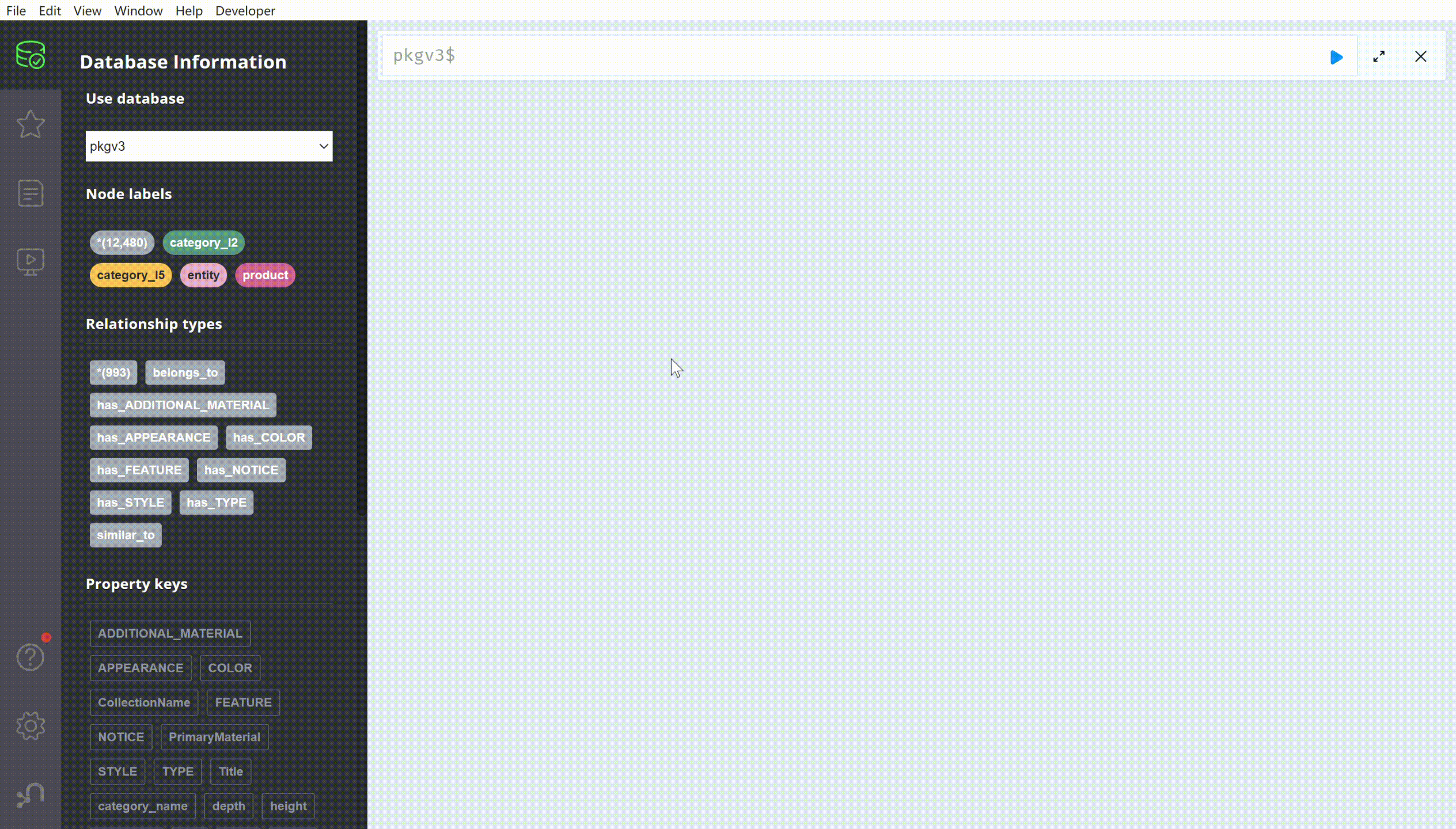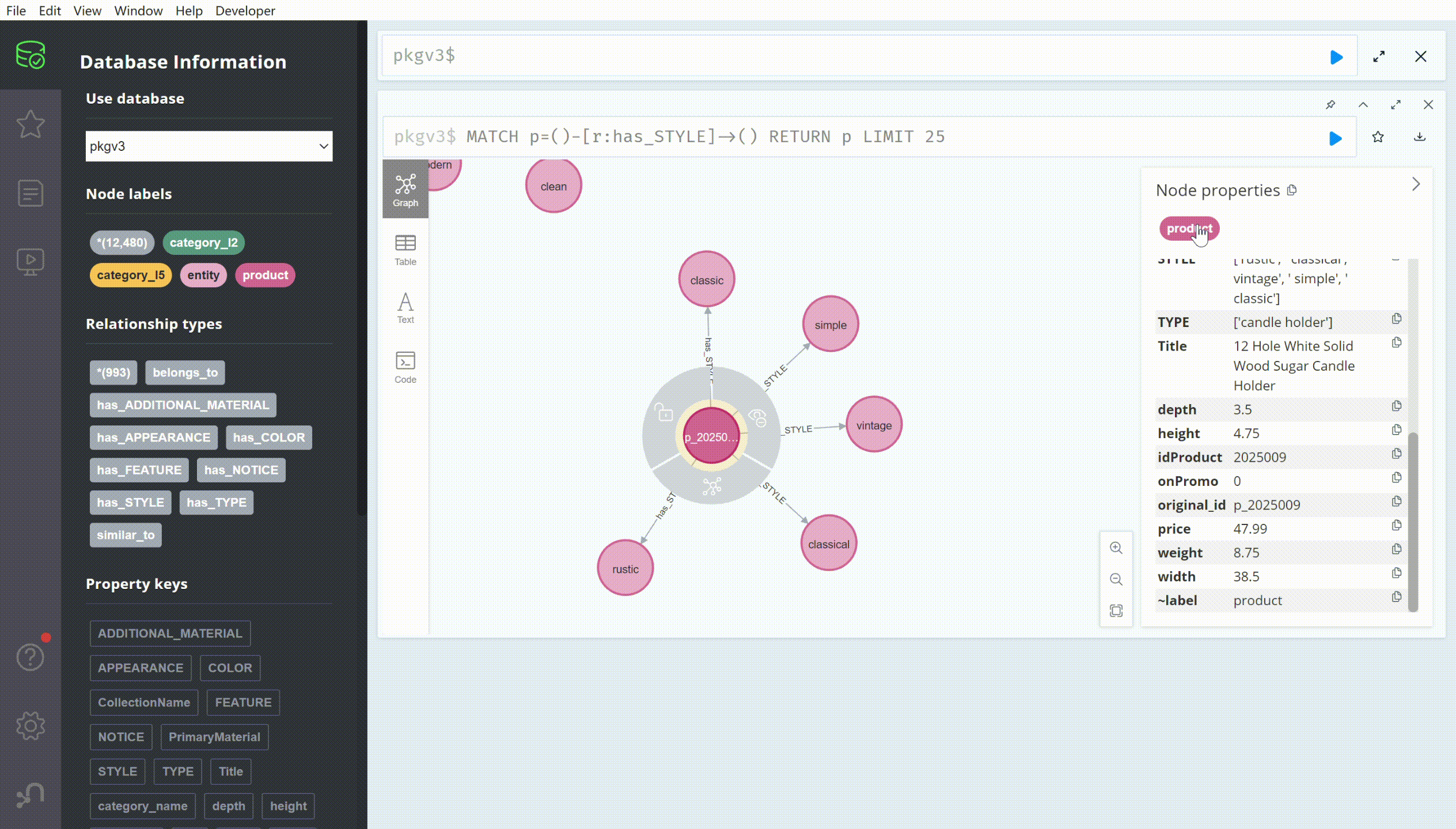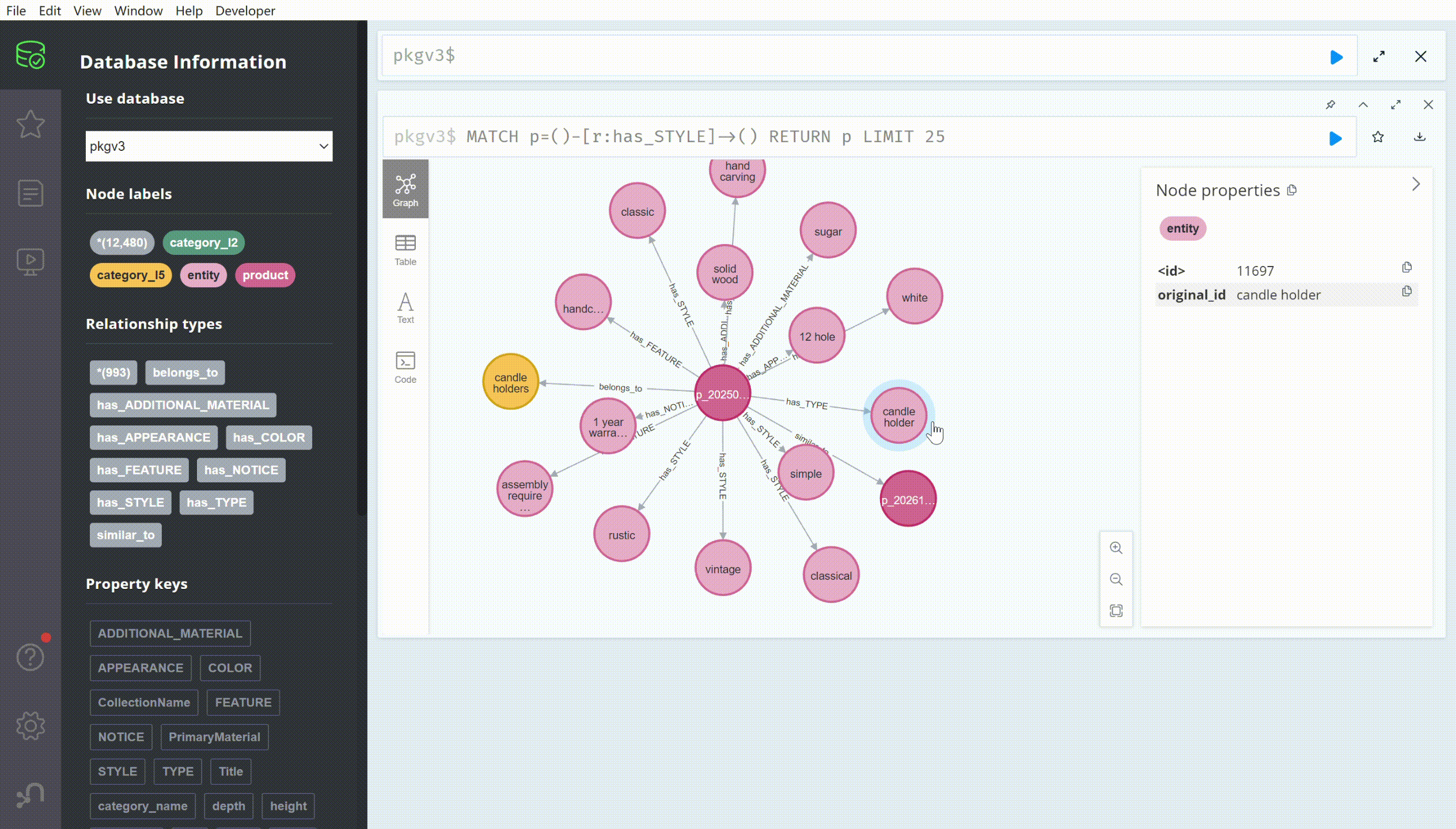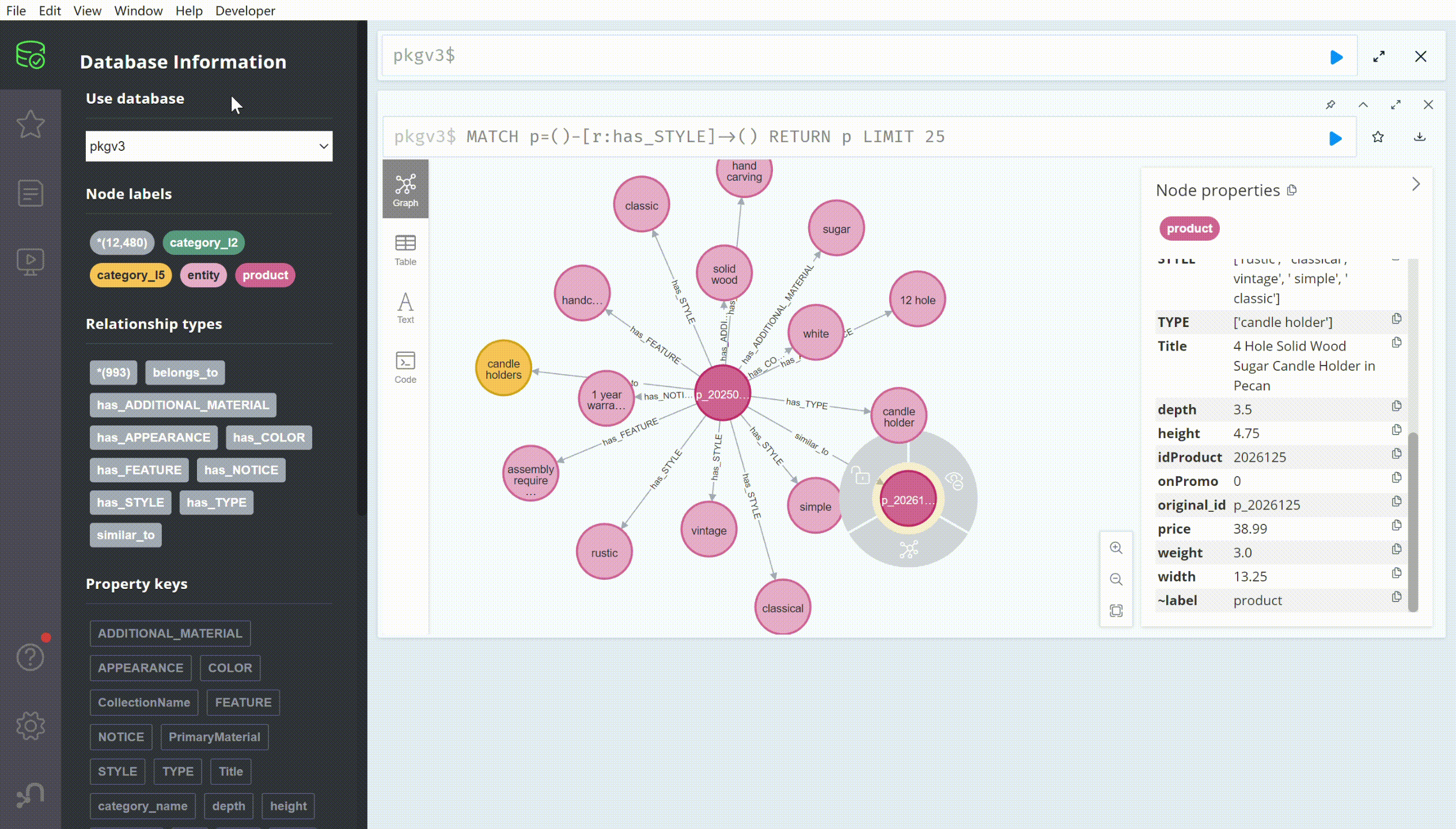
For efficient graph data retrieval and manipulation, we utilized the Neo4j graph database, known for its high performance and scalability. It supports data retrieval using the built-in Cypher query language. The Figure below illustrates an example query from our product knowledge graph in the Neo4j database:
Conclusions
In this Capstone project, we fine-tuned a BERT model to create a custom NER model for extracting key attributes from furniture titles and descriptions. These attributes were then used in the ANNOY model for mapping product similarities. We visualized the product-entity relationships and product-product similarities with a custom Dash app, and utilized the Neo4j database for optimized speed. Our developed product entity recognition system will empower Cymax to capitalize on previously unused information in product titles and descriptions. Integrating this system with Cymax's existing computer vision techniques could further refine their search and recommendation algorithms.
Future work and recommendations
Future directions in this area include exploring a variety of similarity models, such as different approximate nearest neighbors models (Aumüller, Bernhardsson, and Faithfull, 2018). A key focus should be on the hierarchical structure of product categories and subcategories, potentially utilizing Pointcare Embeddings (Nickel and Kiela, 2017) to enhance product matching. This approach requires deeper domain expertise and a more nuanced understanding of product structures. Additionally, incorporating other Cymax data, like image data, could further refine product similarity assessments. Future steps also involve integrating the similarity algorithm with user purchase history to develop a recommendation system. The final stage would be implementing A/B testing of the optimized model to observe its impact on user behavior on Cymax.com. Last but not least, we can implement a poweful recommender system based on the latest graph neural networks (GNN) (DeBlois-Beaucage, 2021) in the future.